HTTP学习笔记(七)
代理的作用
反向代理,它在传输链路中更靠近源服务器,为源服务器提供代理服务。
- 负载均衡
- 常用的负载均衡算法:轮询、一致性哈希。这些算法的目标都是尽量把外部的流量合理地分散到多台源服务器,提高系统的整体资源利用率和性能。
- 健康检查:使用“心跳”等机制监控后端服务器,发现有故障就及时“踢出”集群,保证服务高可用;
- 安全防护:保护被代理的后端服务器,限制 IP 地址或流量,抵御网络攻击和过载;
- 加密卸载:对外网使用 SSL/TLS 加密通信认证,而在安全的内网不加密,消除加解密成本;
- 数据过滤:拦截上下行的数据,任意指定策略修改请求或者响应;
- 内容缓存:暂存、复用服务器响应。
但是,代理作为客户端和源服务器的中间人,在数据上下行的时候可以添加或删除部分头字段,也可以使用黑白名单过滤 body 里的关键字,甚至直接发送虚假的请求、响应,而浏览器和源服务器都没有办法判断报文的真伪。
相关头字段
代理可作为客户端访问服务器,也可作为服务器响应客户端;同时,能够修改请求或者响应,可能会隐藏客户端或者服务端的真实信息,如果想要获得真实信息,可用到Via字段
- Via:(通用字段)每当报文经过一个代理节点,代理服务器就会把自身的信息追加到字段的末尾
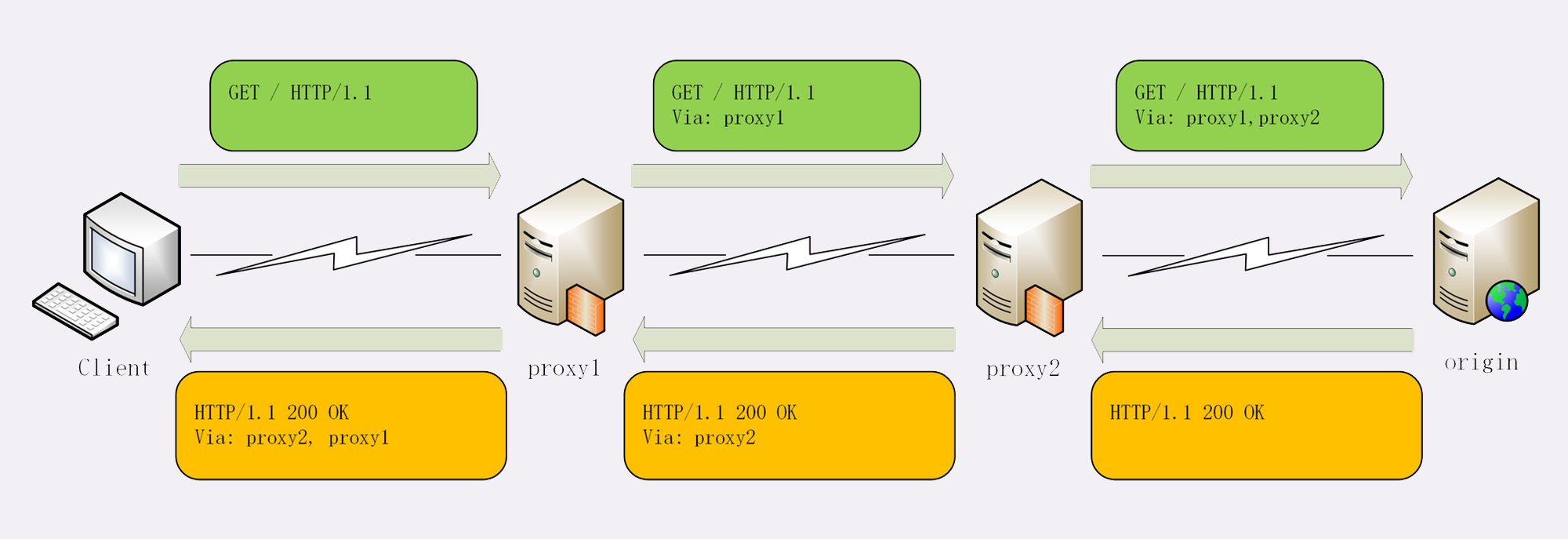
Via 字段只解决了客户端和源服务器判断是否存在代理的问题,还不能知道对方的真实信息。
但服务器的 IP 地址应该是保密的,关系到企业的内网安全,所以一般不会让客户端知道。
不过反过来,通常服务器需要知道客户端的真实 IP 地址,方便做访问控制、用户画像、统计分析。
HTTP 标准里并没有为此定义头字段,但已经出现了很多“事实上的标准”,最常用的两个头字段是“X-Forwarded-For”和“X-Real-IP”。
- X-Forwarded-For:形式上和“Via”差不多,也是每经过一个代理节点就会在字段里追加一个信息。但“Via”追加的是代理主机名(或者域名),而“X-Forwarded-For”追加的是请求方的 IP 地址。所以,在字段里最左边的 IP 地址就是客户端的地址。
- X-Real-IP:是另一种获取客户端真实 IP 的手段,它的作用很简单,就是记录客户端 IP 地址,没有中间的代理信息,相当于是“X-Forwarded-For”的简化版。如果客户端和源服务器之间只有一个代理,那么这两个字段的值就是相同的。
- X-Forwarded-Host:只记录客户端的信息,客户端请求的原始域名
- X-Forwarded-Proto”,只记录客户端的信息,客户端请求的原始协议名。
代理协议
以上字段遇到的问题:
- 通过“X-Forwarded-For”操作代理信息必须要解析 HTTP 报文头,这对于代理来说成本比较高,原本只需要简单地转发消息就好,而现在却必须要费力解析数据再修改数据,会降低代理的转发性能。
- 另一个问题是“X-Forwarded-For”等头必须要修改原始报文,而有些情况下是不允许甚至不可能的(比如使用 HTTPS 通信被加密)。
“代理协议”有 v1 和 v2 两个版本,v1 和 HTTP 差不多,也是明文,而 v2 是二进制格式。v1它在 HTTP 报文前增加了一行 ASCII 码文本,相当于又多了一个头。
这一行文本其实非常简单,开头必须是“PROXY”五个大写字母,然后是“TCP4”或者“TCP6”,表示客户端的 IP 地址类型,再后面是请求方地址、应答方地址、请求方端口号、应答方端口号,最后用一个回车换行(\r\n)结束。
1 | PROXY TCP4 1.1.1.1 2.2.2.2 55555 80\r\n |
在 GET 请求行前多出了 PROXY 信息行,客户端的真实 IP 地址是“1.1.1.1”,端口号是 55555。
服务器看到这样的报文,只要解析第一行就可以拿到客户端地址,不需要再去理会后面的 HTTP 数据,省了很多事情。
这样,可以在不改动原始报文的情况下传递客户端的真实 IP。
不过代理协议并不支持“X-Forwarded-For”的链式地址形式,所以拿到客户端地址后再如何处理就需要代理服务器与后端自行约定。
知识补充:
- “Via”是HTTP协议里规定的标准头字段,但有的服务器返回的响应报文里会使用“X-Via”,含义是相同的。
- 因为HTTP是明文传输,请求头很容易被窜改,所以“X-Forwarded-For”也不是完全可信的。
缓存代理
代理服务收到源服务器发来的响应数据后需要做两件事。
- 把报文转发给客户端;
- 把报文存入自己的 Cache 里。
再有相同的请求,代理服务器就可以直接发送 304 或者缓存数据,不必再从源服务器那里获取。这样就降低了客户端的等待时间,同时节约了源服务器的网络带宽。
缓存代理既可以作为客户端向源服务器发送网络请求,也可以作为服务器响应客户端的请求。(既是客户端又是服务器,所以既可以用客户端的缓存控制策略也可以用服务器端的缓存控制策略,(即:各种Cache-Control头字段))
源服务器的缓存控制
客户端也有缓存,但是与代理缓存不同的地方在于,客户端的缓存仅仅是客户端自身使用,但是代理的缓存会为很多的客户端提供服务。
头字段
- Cache-Control:(通用字段)
- 属性
public&&private:区分代理缓存和客户端缓存。默认public- public:缓存完全开放,谁都可以存,谁都可以用。
- private:缓存只能在客户端保存,是用户“私有”的,不能放在代理上与别人共享
proxy-revalidate:- 区分:must-revalidate:只要过期就必须回源服务器验证;
proxy-revalidate要求代理的缓存过期后必须验证,客户端不必回源,只验证到代理这个环节就行了
s-maxage:代理缓存的生命周期。只限定在代理上能够存多久,而客户端仍然使用“max-age”。- 若响应报文同时指定了
s-maxage和max-age,则缓存代理参考s-maxage,客户端参考max-age - 若相应报文只指定了
max-age,缓存代理和客户端均参考max-age
- 若响应报文同时指定了
no-transform:代理专用属性。。代理有时候会对缓存下来的数据做一些优化,比如把图片生成 png、webp 等几种格式,方便今后的请求处理,而“no-transform”就会禁止这样做,不许“偷偷摸摸搞小动作”。max-age、no-store、no-cache它们也是同样作用于代理和源服务器。
1 | private, max-age=5 |
1 | public, max-age=5, s-maxage=10 |
1 | max-age=30, proxy-revalidate, no-transform |
注意:源服务器在设置完“Cache-Control”后必须要为报文加上“Last-modified”或“ETag”字段。否则,客户端和代理后面就无法使用条件请求来验证缓存是否有效,也就不会有 304 缓存重定向。
客户端缓存控制
相关头字段
Cache-Control:- 属性:
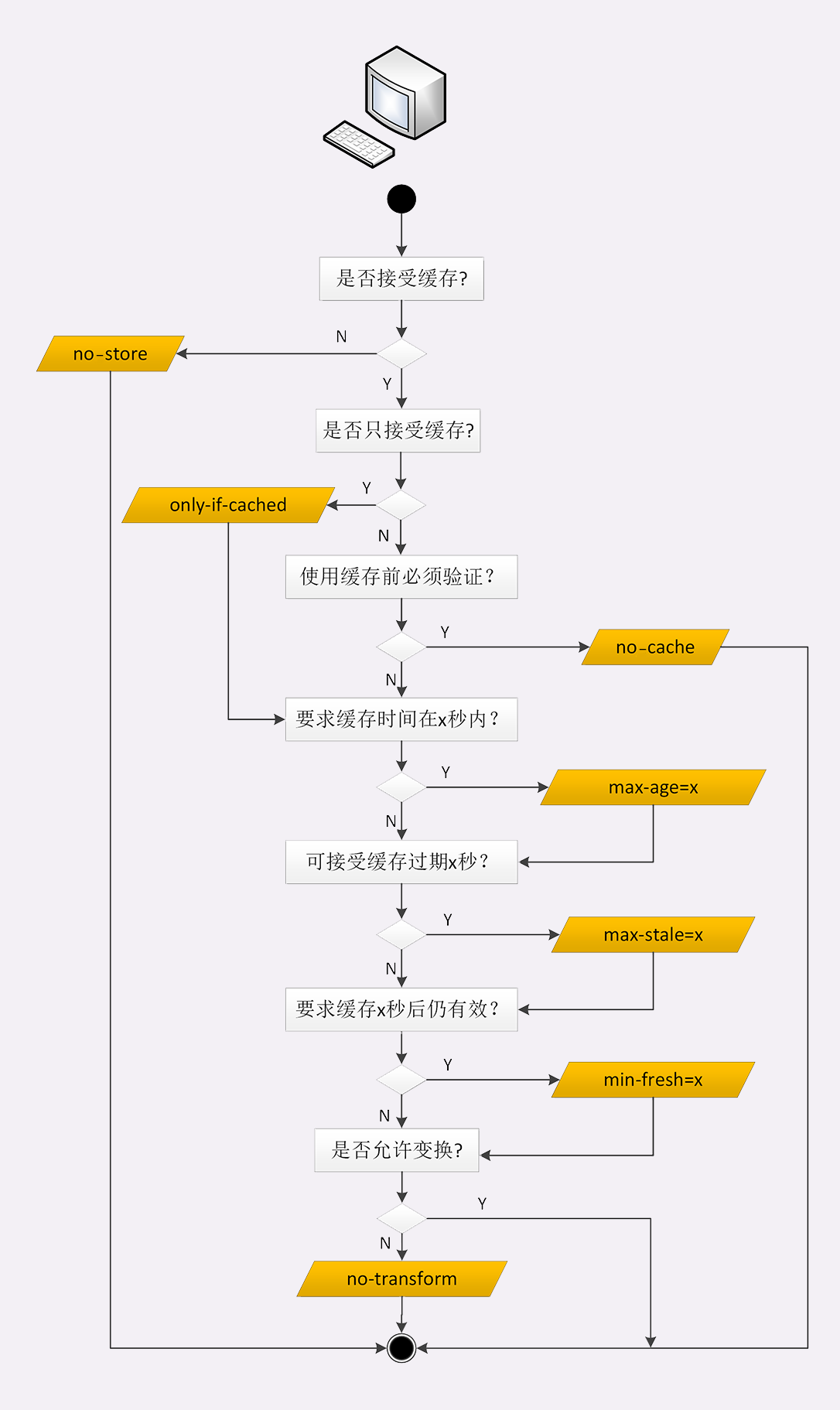
max-stale:如果代理上的缓存过期了也可以接受,但不能过期太多,超过 x 秒也会不要min-fresh:缓存必须有效,而且必须在 x 秒后依然有效。only-if-cached:表示只接受代理缓存的数据,不接受源服务器的响应;如果代理上没有缓存或者缓存过期,就应该给客户端返回一个 504(Gateway Timeout)。
1 | max-age=5, max-stale=2 |
1 | max-age=10, min-fresh=5 |
代理在响应报文里还会额外加了“X-Cache”“X-Hit”等自定义头字段,表示缓存是否命中和命中率,方便观察缓存代理的工作情况。
其他问题
- Vary:Vary是客户端与服务端在使用Accept和Content-Type等字段进行响应报文具体内容协商时,由服务端在响应头添加的字段,用来记录服务器在与客户端进行内容协商时参考的请求字段。
- 这个 Vary 字段表示服务器依据了 Accept-Encoding、User-Agent 和 Accept 这三个头字段,然后决定了发回的响应报文,具体步骤见下:
1 | // 1.客户端1请求数据A |
如果不使用Vary字段,单靠请求URL和请求方法,其他的客户端可能会拿到错误的数据。
这便是 Vary 头字段的作用:让代理服务器的缓存命中更多的决定因子,而不仅仅是依据请求 URL 和请求方法来决定是否命中。
参考文档:https://juejin.cn/post/6844903981907443720
- Purge:缓存清理”,它对于代理也是非常重要的功能
- 过期的数据应该及时淘汰,避免占用空间;
- 源站的资源有更新,需要删除旧版本,主动换成最新版(即刷新);
- 有时候会缓存了一些本不该存储的信息,例如网络谣言或者危险链接,必须尽快把它们删除。
清理缓存的方法有很多,比较常用的一种做法是使用自定义请求方法“PURGE”,发给代理服务器,要求删除 URI 对应的缓存数据。